L’histoire de l’apprentissage automatique
L’histoire de l’apprentissage machine est souvent associée à celle de l’intelligence artificielle. L’apprentissage machine, considéré comme un moyen technique qui s’inspire de l’intelligence biologique, a poussé, dès ses débuts, les scientifiques à toujours miser sur la création d’ordinateurs dotés d’une capacité d’apprentissage et d’autoadaptation.
Les fondements de l’intelligence artificielle
Les fondements de l’intelligence artificielle remontent aux années 1950, alors qu’Alan Turing, fondateur du test de Turing, mesure la capacité d’un ordinateur à interagir comme un être humain.
Selon Turing, les ordinateurs sont considérés comme étant intelligents dès qu’ils peuvent tenir une conversation rationnelle avec un opérateur humain sans que celui-ci ne se rende compte qu’il interagit avec un ordinateur.
À l’époque de Turing, les technologies informatiques étaient à un stade embryonnaire; les ordinateurs possédaient des capacités de mémoire et de calcul extrêmement faibles.
La création du perceptron
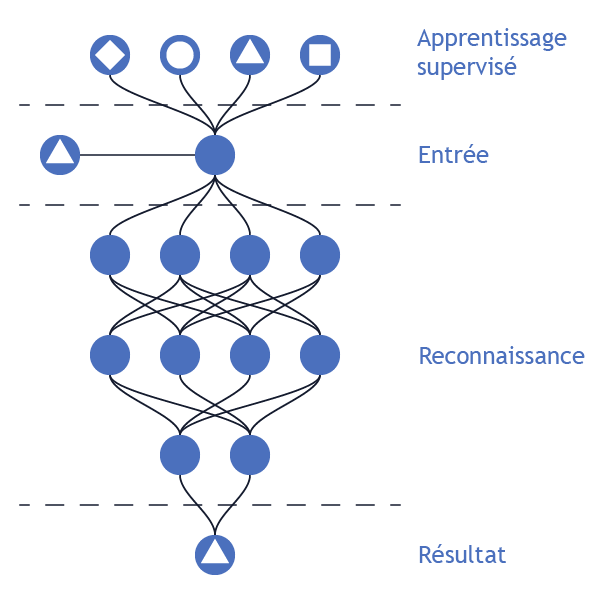
En 1958, Frank Rosenblatt du laboratoire aéronautique de l’université Cornell, présente le Perceptron, le premier algorithme d’apprentissage supervisé basé sur les réseaux de neurones artificiels. Cet algorithme est capable de reconnaître des formes élémentaires. Il procède à une simple classification binaire, par exemple classer une nouvelle forme en une forme X ou Y.
Le terme apprentissage machine popularisé
Le terme apprentissage machine devient populaire en 1959 grâce aux travaux du chercheur Arthur Samuel. Il présente un jeu de dames capable d’apprendre à mesure que le jeu évolue à partir de données historiques stockées dans sa mémoire.
L’invention des algorithmes de rétropropagation
La publication de David Everett Rumelhart, Geoffrey Everest Hinton et Ronald Williams intitulé « Learning Representations by Back-Propagating Errors », dans la revue scientifique Nature, est considérée comme une découverte majeure dans la discipline de l’apprentissage machine. Il s’agit d’une méthode de rétropropagation d’un signal permettant à un réseau de neurones artificiels de corriger ses prédictions et d’ajuster automatiquement ses fonctions.
Avec cette avancée, le progrès de la discipline atteint un certain plateau; les percées scientifiques se raréfient et, de ce fait, l’intérêt de la communauté scientifique à cet égard se dissipe.
Le développement d’un algorithme de reconnaissance d’images performant
En 2012, le professeur Geoffrey Hinton et deux de ses étudiants, Alex Krizhevsky et Ilya Sutskever, réussissent à entraîner un algorithme de reconnaissance d’images capable d’identifier automatiquement les objets d’une image à un taux d’exactitude jamais atteint auparavant, soit 84,7 % à l’aide de processeurs graphiques.
La multiplication des librairies d’information ouverte
Plusieurs grandes entreprises (Google, Microsoft, IBM, etc.) et d’importants laboratoires universitaires (Université de Montréal, University of Toronto, Stanford, MIT, etc.) travaillent d’arrache-pied pour démocratiser la discipline de l’apprentissage machine en mettant à la disposition des chercheurs et des développeurs des librairies d’informations ouvertes (open source) telles que TensorFlow, PyTorch, etc.
La disponibilité de ces outils, des données d’entraînement et de la capacité de calcul permet une croissance fulgurante du nombre de cas d’usage associés à l’apprentissage machine.
Cette technologie démontre une performance inédite et un potentiel quasi infini comme le montre le succès de l’algorithme Alpha Go de Deep Mind qui a réussi à vaincre, à plusieurs reprises, le champion du monde du jeu Go ou la performance du nouvel algorithme de traitement de langage naturel GPT3 créé par OpenAI.